摘自《Netty权威指南》
在我们讨论Netty线程模型的时候,都会想到经典的Reactor线程模型
Reactor单线程模型
Reactor单线程模型,是指所有的IO操作都在同一个NIO线程上面完成,NIO线程职责如下:
- 作为NIO服务端,接收客户端的TCP连接
- 作为NIO客户端,向客户端发起TCP连接
- 读取通信对端的请求或者应答消息
- 向通信对端发送消息或者应答消息
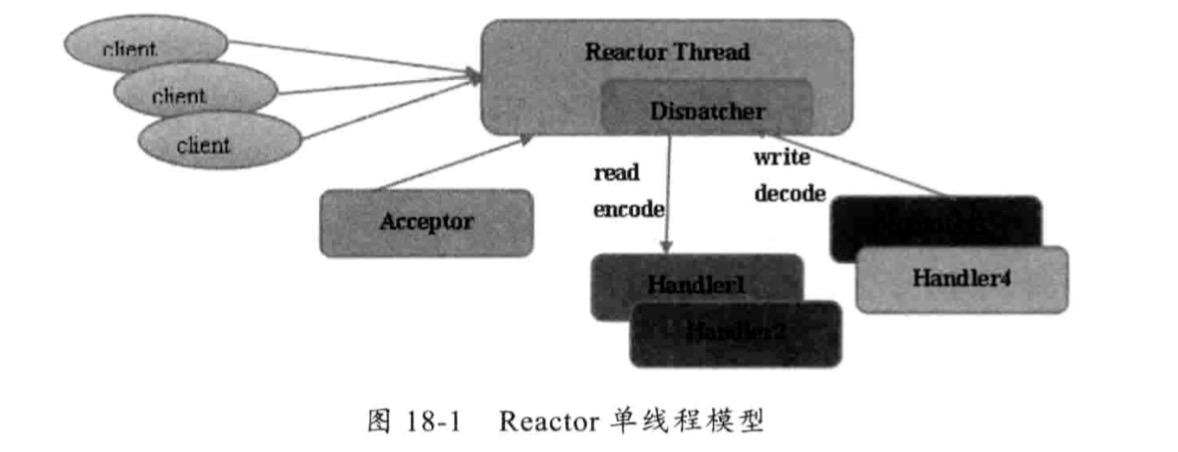
由于 Reactor 模式使用的是异步非阻塞IO,所有的IO操作都不会导致阻塞,理论上一个线程可以独立处理所有IO相关操作。例如通过 Acceptor 类接收客户端的TCP连接,当链路建立成功后,通过 Dispatch 将对应的 ByteBuffer 派发到指定的 Handler 上,进行消息解码,用户线程消息编码后通过NIO线程将消息发送给客户端
这种模型对于高负载、大并发的应用场景却不适合,原因如下:
- 一个NIO线程同时处理成百上千的链路,性能上无法支撑,无法满足海量消息的编码、解码、读取和发送
- 当NIO线程负载锅中之后,处理速度将变慢,会导致大量客户端连接超时,超时往往会进行重发,会导致大量消息积压和处理超时,成为性能瓶颈
- 一旦NIO线程出现意外,或者进入死循环,会导致整个系统通信模块不可用
Reactor多线程模型
Reactor多线程模型与单线程最大的区别就是有一组NIO线程来处理IO操作:
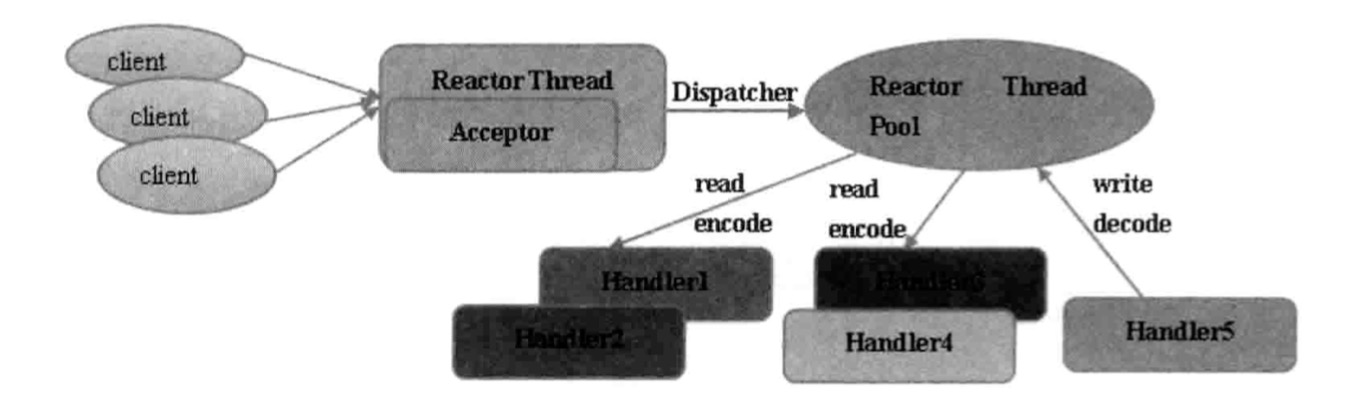
特点如下:
- 有专门一个NIO线程(Acceptor线程)用于监听TCP连接请求
- 网络IO操作(读、写等)由一个NIO线程池负责,线程池可以用JDK线程池实现,它包含一个任务队列和N个可用的线程,这些NIO线程负责消息的读取、解码、编码和发送
- 一个NIO线程可以同时处理N条链路,但是一个链路只对应一个NIO线程,防止发生并发操作问题
在绝大多数场景下,该模型可以满足性能要求,但是当并发百万客户端连接,或者服务端需要对客户端进行安全认证,单独一个Acceptor线程可能存在性能不足的问题
主从Reactor多线程模型
它的特点是:服务端用于接收客户端连接的不再是一个单独的NIO线程,而是一个线程池。Acceptor接收到客户端TCP连接请求并处理完成后(可能包含接入认证等),将新创建的 SocketChannel 注册到IO线程池(sub reactor线程池)的某个线程上,由它负责 SocketChannel 的读写和编解码工作,Acceptor线程池只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端 subReactor 线程池的IO线程上
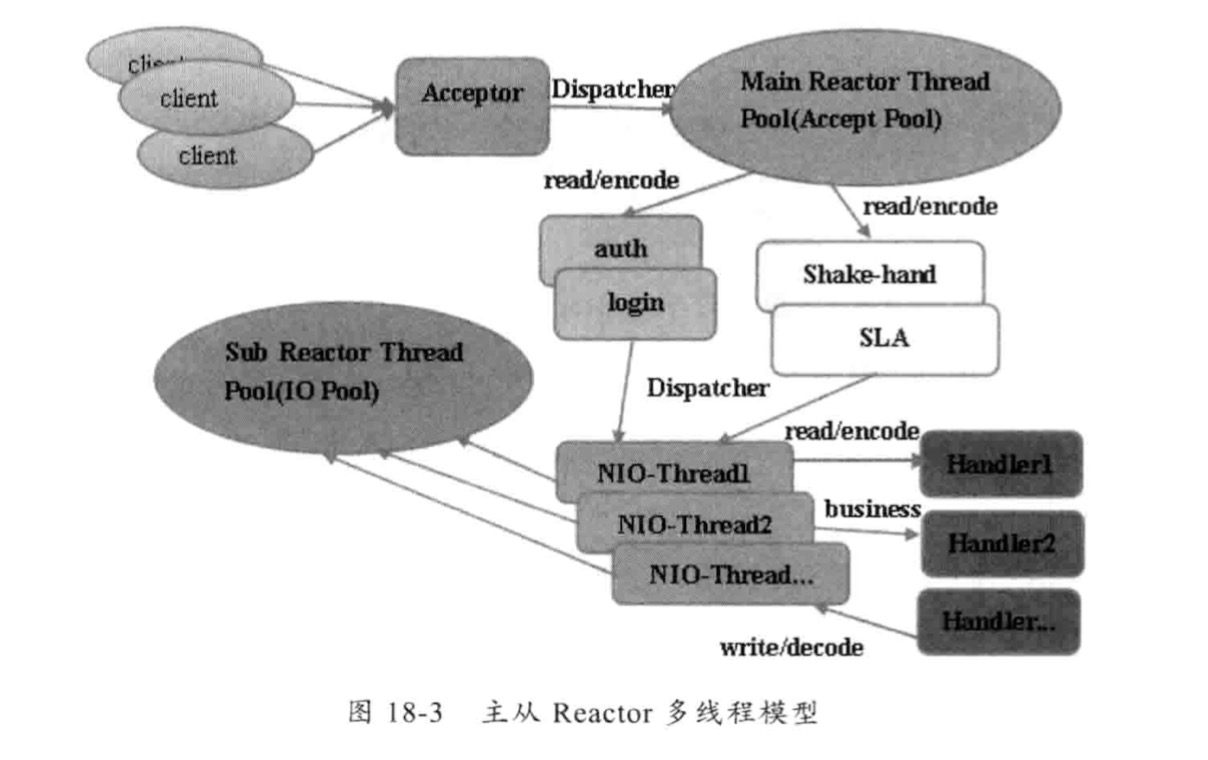
这样就可以解决一个服务端无法有效处理所有客户端连接的性能不足问题
Netty线程模型
Netty线程模型不是一成不变的,它取决于用户的启动参数配置,可以支持Reactor单线程模型、Reactor多线程模型和主从Reactor多线程模型
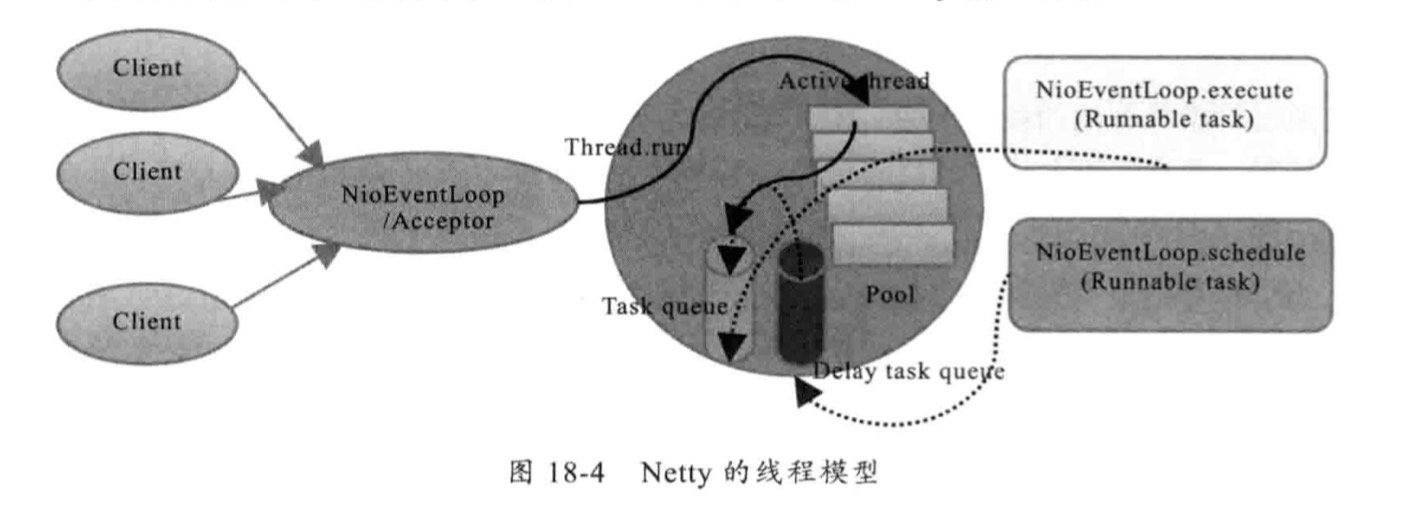
通过服务端代码了解其线程模型:
1 | NioEventLoopGroup bossGroup = new NioEventLoopGroup(); |
创建了两个 NioEventLoopGroup,一个用于接收客户端的TCP连接,另一个用户处理IO相关读写操作,或者执行系统Task、定时任务Task等
用于接收客户端请求的线程池职责:
- 接收客户端TCP连接,初始化 Channel 参数
- 将链路状态变更事件通知给 ChannelPipeline
处理IO操作的 Reactor 线程池职责:
- 异步读取通信对端的数据,发送读事件到 ChannelPipeline
- 异步发送消息到通信对端,调用 ChannelPipeline 的消息发送接口
- 执行系统调用Task
- 执行定时任务Task,如链路空闲状态检测定时任务
为了尽可能提升性能,Netty在很多地方进行了无锁化的设计,比如在IO线程内部进行串行操作,避免多线程竞争导致的性能下降,表面上看这种设计CPU利用率不高,并发度不够,但是通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部的无锁化串行线程设计比一个队列多个工作线程的模型性能更好
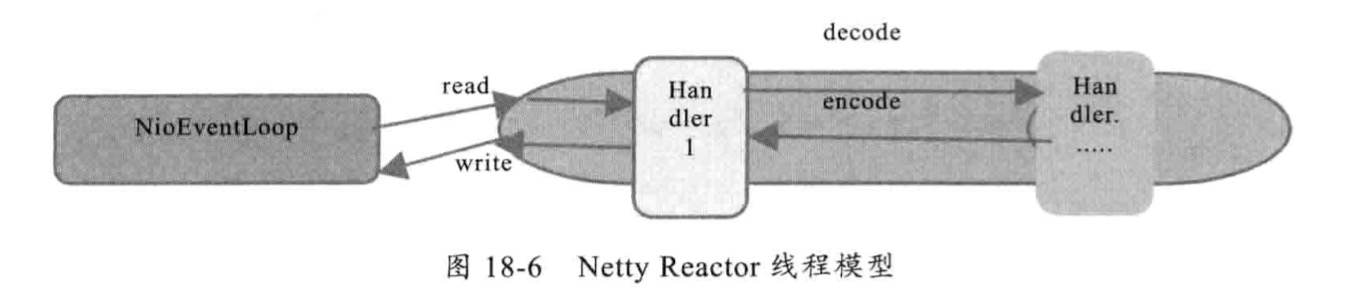
Netty的 NioEventLoop 读取到消息后,直接调用 ChannelPipeline 的 fireChannelRead(Object msg)。只要用户不主动切换线程,一直都是由 NioEventLoop 调用用户的 Handler,期间不进行线程切换,避免多线程操作导致的锁的竞争
最佳实践
Netty多线程编程最佳实践如下:
- 创建两个
NioEventLoopGroup,用户逻辑隔离NIO Acceptor和NIO IO线程 - 尽量不要在
ChannelHandler中启动用户线程(解码后用于将消息派发到后端业务线程的例外) - 解码要放在NIO线程调用的解码Handler中进行,不要切换到用户线程中完成消息的解码
- 如果业务逻辑操作非常简单,没有可能会导致线程被阻塞的磁盘操作、数据库操作、网络操作等,可以直接在NIO线程上完成业务逻辑,不需要切换到用户线程
- 乳沟业务逻辑处理复杂,不要在NIO线程上完成,建议将解码后的消息封装成Task,派发到业务线程池中由业务线程执行,以保证NIO线程尽快被释放,处理其它IO操作
推荐的线程数量计算公式:
- 线程数量 = (线程总时间/瓶颈资源时间) * 瓶颈资源的线程并行数
- QPS = 1000/线程总时间 * 线程数
由于用户场景的不同,对于一些复杂的系统,实际上很难计算,职能根据测试数据和用户场景,结合公式给出一个相对合理的范围,然后对范围内的数据进行性能测试,选择相对最优值