再master/slave模式中,当master遇到异常中断后,需要从slave中选举一个新的master继续对外提供服务,这种机制有很多,比如在zk中的leader选举、kafka中可以基于zk的节点实现master选举。所以在redis中也需要一种机制去实现master的决策,redis没有提供自动master选举功能,需要借助一个哨兵来进行监控。
哨兵的作用就是监控redis系统的运行情况,功能包括两个:
- 监控master和slave是否正常运行
- master出现故障时自动将slave数据库升级为master
哨兵是一个独立的进程,使用哨兵后的架构图:
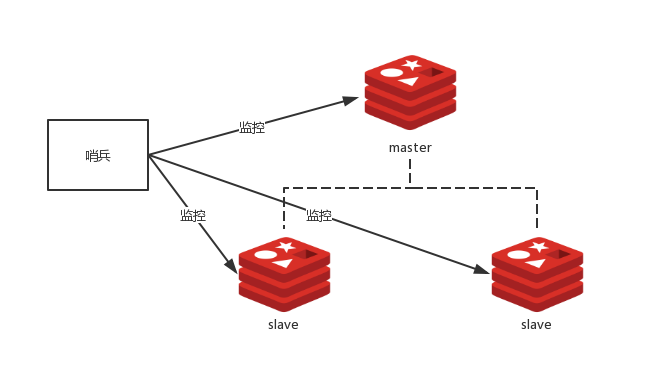
哨兵集群
为了解决master选举问题,又引出了一个单点问题,就是哨兵的可用性问题,在一个一主多从的redis系统中,可以使用多个哨兵进行监控来保证系统足够稳定,此时哨兵不仅会监控master和slave,同时还会互相监控。这种方式成为哨兵集群,哨兵集群需要解决故障发现和master决策协商机制问题。
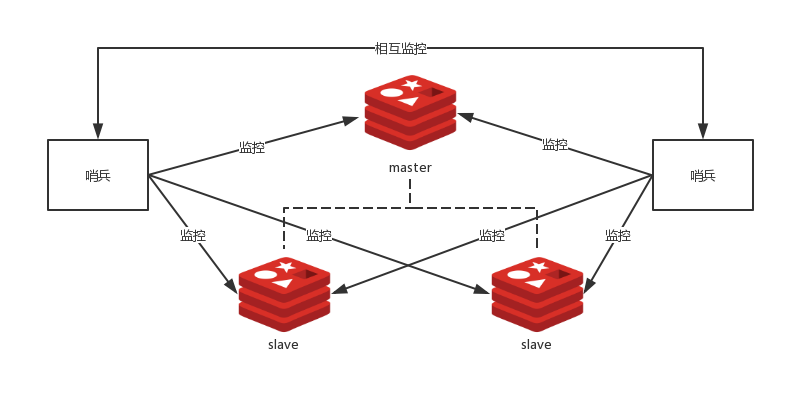
哨兵之间的相互感知
哨兵节点之间会因为共同监视同一个master从而产生关联,一个新加入的哨兵节点需要和其他监视相同master节点的哨兵相互感知:
- 需要相互感知的哨兵都向他们共同监视的master节点订阅
channel:sentinel:hello - 新键入的哨兵节点向这个channel发布一条消息,包含自己本身的信息,这样订阅了这个channel的哨兵就可以发现这个新的哨兵
- 新加入的哨兵和其他哨兵节点建立长连接
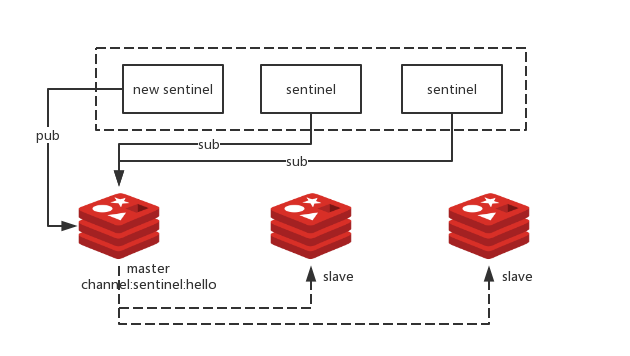
master故障发现
sentinel节点会定期向master节点发送心跳包来判断存活状态,一旦master节点没有正确响应,sentinel会把master设置为“主观不可用状态”,然后会把“主观不可用”发送给其他所有的sentinel节点去确认,当确认的sentinel节点数大于quorum时,则会认为master是“客观不可用”,接着就开始进入选举新的master流程。
这里会遇到一个问题,就是sentinel中,本身是一个集群,如果多个节点同时发现master节点达到客观不可用状态,那谁来决策选择哪个节点作为master呢?
这个时候就需要从sentinel集群中选择一个leader来做决策,这里用到了一致性算法Raft算法,它和Paxos算法类似,都是分布式一致性算法,但是它比Paxos算法更容易理解,它们都是基于投票算法,只要保证半数节点通过提议即可
动画演示地址:http://thesecretlivesofdata.com/raft
配置实现
创建sentinel.conf文件,文件主要配置:1
2
3
4
5
6
7
8
9
10
11// sentinel monitor name ip port quorum
// name表示要监控的master的名字,自定义
// ip和port表示master的ip和端口号
// quorum表示最低通过票数,也就是说需要几个哨兵节点统一才可以
sentinel monitor mymaster 192.168.11.131 6397 1
// 表示如果5s内mymaster没响应,就认为SDOWN
sentinel down-after-milliseconds mymaster 5000
// 表示15s后,mymaster仍没活过来,则启动failover,从剩下的slave中选一个升级为master
sentinel failover-timeout mymaster 15000
两种方式启动哨兵:1
2redis-sentinel sentinel.conf
redis-server /path/sentinel.conf --sentinel
哨兵监控一个系统时,只需要配置监控master即可,哨兵会自动发现所有slave